

This is the beginning of the unbundled database era – TechCrunch
Thanks to the cloud, the amount of data being generated and stored has exploded in scale and volume.
Every aspect of the enterprise is being instrumented for data, so new operations are built based on that data, pushing every company into becoming a data company.
One of the most profound and maybe non-obvious shifts driving this is the emergence of the cloud database. Services such as Amazon S3, Google BigQuery, Snowflake and Databricks have solved computing on large volumes of data and have made it easy to store data from every available source.
The enterprise wants to store everything they can in the hopes of being able to deliver improved customer experiences and new market capabilities.
It’s a good time to be a database company
Database companies have raised over $8.7 billion over the last 10 years, with almost half of that, $4.1 billion, just in the last 24 months, according to CB Insights.
It’s not surprising given the sky-high valuations of Snowflake and Databricks. The market doubled in the last four years to almost $90 billion, and is expected to double again over the next four years. It’s safe to say there is a huge opportunity to go after.
See here for a solid list of database financings in 2021.
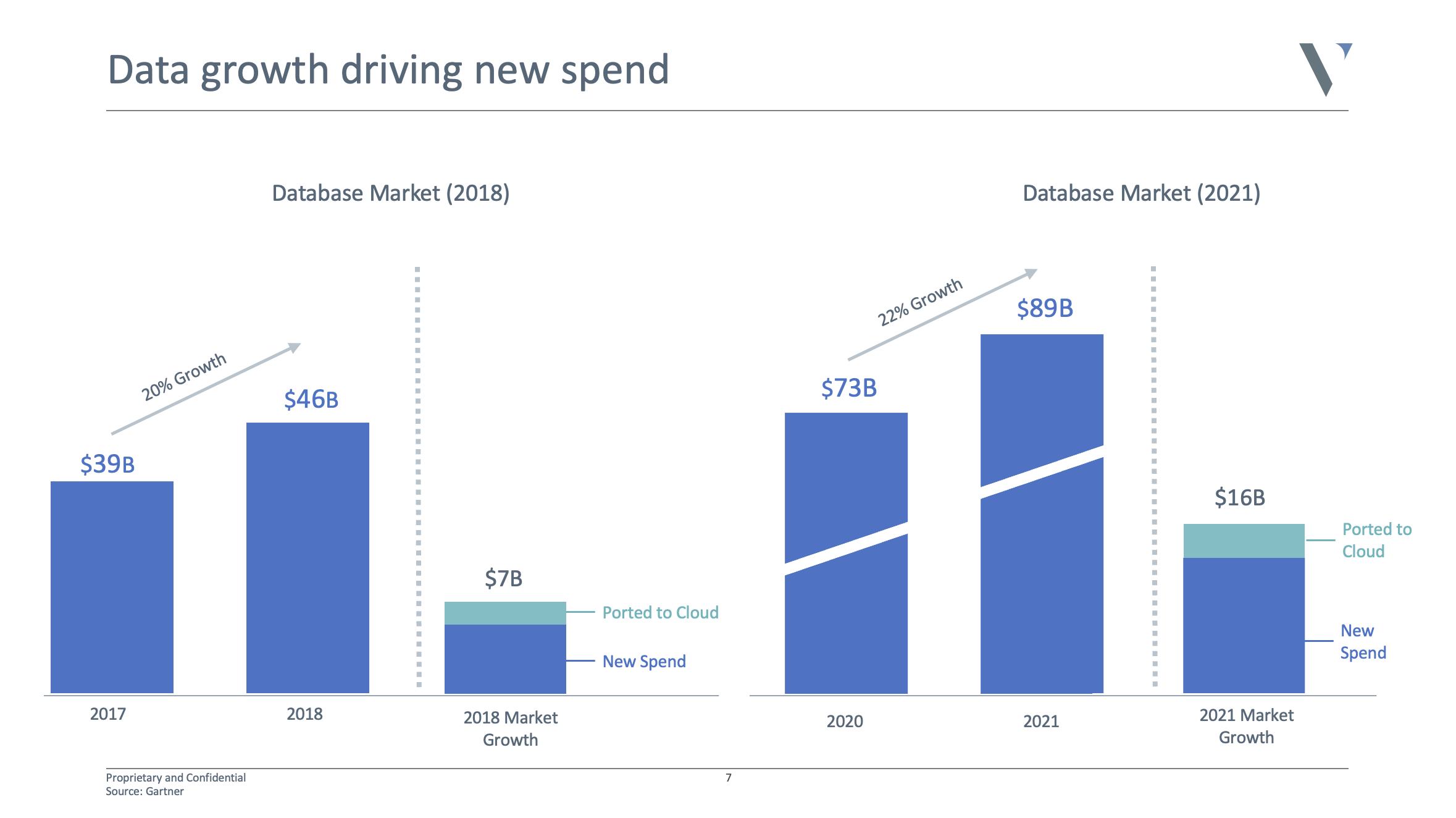
Database growth is driving spend in the enterprise. Image Credits: Venrock
20 years ago, you had one option: A relational database
Today, thanks to the cloud, microservices, distributed applications, global scale, real-time data and deep learning, new database architectures have emerged to solve for new performance requirements.
We now have different systems for fast reads and fast writes. There are also systems specifically to power ad-hoc analytics or for data that is unstructured, semi-structured, transactional, relational, graph or time-series, as well as for data used for cache, search, based on indexes, events and more.
It may come as a surprise, but there are still billions of dollars in Oracle instances still powering critical apps today, and they likely aren’t going anywhere.
Each system comes with different performance needs, including high availability, horizontal scale, distributed consistency, failover protection, partition tolerance and being serverless and fully managed.
As a result, enterprises, on average, store data across seven or more different databases. For example, you may have Snowflake as your data warehouse, Clickhouse for ad-hoc analytics, Timescale for time-series data, Elastic for their search data, S3 for logs, Postgres for transactions, Redis for caching or application data, Cassandra for complex workloads and Dgraph* for relationship data or dynamic schemas.
That’s all assuming you are collocated to a single cloud and you’ve built a modern data stack from scratch.
The level of performance and guarantees from these services and platforms is on a very different level compared with what we had five to 10 years ago. At the same time, the proliferation and fragmentation of the database layer are increasingly creating new challenges.
For example, syncing across different schemas and systems, writing new ETL jobs to bridge workloads across multiple databases, constant cross-talk and connectivity issues, the overhead of managing active-active clustering across so many different systems, or data transfers when new clusters or systems come online. Each of these has different scaling, branching, propagation, sharding and resource requirements.
What’s more, we now have new databases every month that aim to solve the next challenge of enterprise scale.
The new-age database
So the question is, will the future of the database continue to be defined as it is today?


