

AWS expands its serverless offerings with Aurora Serverless v2 and Sagemaker Serverless Inference – TechCrunch
At its AWS Summit San Francisco, Amazon’s cloud computing arm today announced a number of product launches, including two focused on its serverless portfolio. The first of these is the GA launch of Amazon Aurora Serverless V2, its serverless database service, which can now scale up and down significantly faster than the previous version and is able to scale in more fine-grained increments. The other is the GA launch of SageMaker Serverless Inference. Both of these services first launched into preview at AWS re:Invent last December.
Swami Sivasubramanian, the VP for database, analytics and ML at AWS, told me that more than 100,000 AWS customers today run their database workloads on Aurora and that the service continues to be the fastest-growing AWS service. He noted that previously, in version 1, scaling the database capacity would take five to forty seconds and the customers had to double the capacity.
“Because it’s serverless, customers then didn’t have to worry about managing database capacity,” Sivasubramanian explained. “However, to run a wide variety of production workloads with [Aurora] Serverless V1, when we were talking to customers more and more, they said, customers need the capacity to scale in fractions of a second and then in much more fine-grained increments, not just doubling in terms of capacity.”
Sivasubramanian argues that this new system can save users up to 90 percent of their database cost when compared to the cost of provisioning for pre-capacity. He noted that there are no tradeoffs in moving to v2 and that all of the features in v1 are still available. The team changed the underlying computing platform and storage engine, though, so that it’s now possible to scale in these small increments and do so much faster. “It’s a really remarkable piece of engineering done by the team,” he said.
Already, AWS customers like Venmo, Pagely and Zendesk are using this new system, which went into preview last December. AWS argues that it’s not a very heavy lift to convert workloads that currently run on Amazon Aurora Serverless v1 to v2.
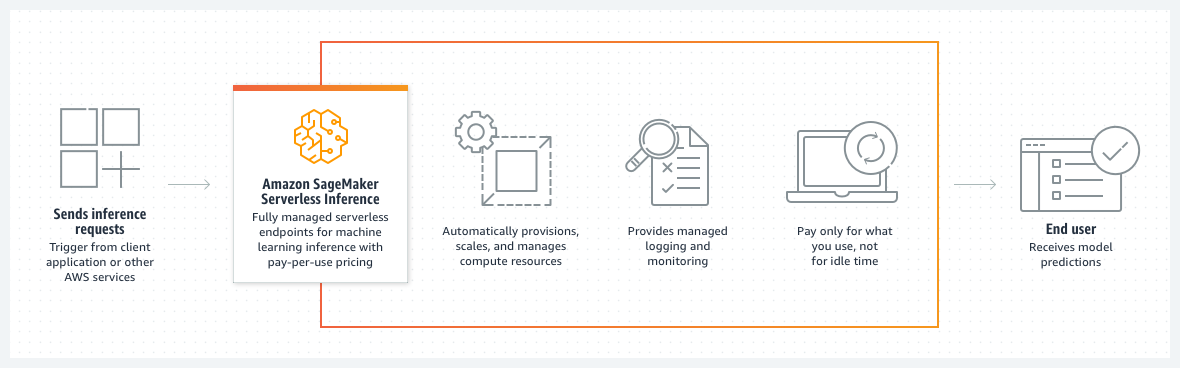
Image Credits: AWS
As for SageMaker Serverless Inference, which is now also generally available, Sivasubramanian noted that the service gives businesses a pay-as-you-go service for deploying their machine learning models — and especially those that often sit idle — into production. With this, AWS now offers four inferencing options: Serverless Inference, Real-Time Inference for workloads where low latency is paramount, SageMaker Batch Transform for working with batches of data, and SageMaker Asynchronous Inference for workloads with large payload sizes that may require long processing times. With that much choice, it’s maybe no surprise that AWS also offers the SageMaker Inference Recommender to help users figure out how to best deploy their models.


 | TechCrunch")