

‘Inaudible’ watermark could identify AI-generated voices
The growing ease with which anyone can create convincing audio in someone else’s voice has a lot of people on edge, and rightly so. Resemble AI’s proposal for watermarking generated speech may not fix it in one, but it’s a step in the right direction.
AI-generated speech is being used for all kinds of legitimate purposes, from screen readers to replacing voice actors (with their permission, of course). But as with nearly any technology, speech generation can be turned to malicious ends as well, producing fake quotes by politicians or celebrities. It’s highly desirable to find a way to tell real from fake that doesn’t rely on a publicist or close listening.
Watermarking is a technique by with an image or sound is imprinted with an identifiable pattern that shows its origin. We’ve all seen obvious watermarks like a logo on an image, but not all of them are so noticeable.
In images, a hidden watermark may hide the pattern at a pixel-by-pixel level, leaving the image looking unmodified to human eyes but identifiable to a computer. Same for audio: an occasional quiet sound encoding the information might not be something a casual listener would hear.
The trouble with these subtle watermarks is that they tend to be obliterated by even minor modifications to the media. Resize the image? There goes your pixel-perfect code. Encode the audio for streaming? The secret tones are compressed right out of existence.
Resemble AI is among a new cohort of generative AI startups aiming to use finely tuned speech models to produce dubs, audiobooks, and other media ordinarily produced by regular human voices. But if such models, perhaps trained on hours of audio provided by actors, were to fall into malicious hands, these companies may find themselves at the center of a PR disaster and perhaps serious liability. So it’s very much in their interest to find a way to make their recordings both as realistic as possible and also easily verifiable as being generated by AI.
PerTh is Resemble’s proposed watermarking process for this purpose, an awkward combination of “perceptual” and “threshold.”
“We have developed an additional layer of security that uses machine learning models to both embed packets of data into the speech content that we generate, and recover said data at a later point,” the company writes in a blog post explaining the technology. “Because the data is imperceptible, while being tightly coupled to the speech information, it is both difficult to remove, and provides a way to verify if a given clip was generated by Resemble. Importantly, this ‘watermarking’ technique is also tolerant of various audio manipulations like speeding up, slowing down, converting to compressed formats like MP3, etc.”
It relies on a quirk of how humans process audio, by which tones with high audibility essentially “mask” nearby tones of lesser amplitude. So if someone laughs and it produces peaks at the 5,000 Hz, 8,000 Hz, and 9,200 Hz frequencies, you can slip in structured tones that occur simultaneously within a few hertz, and they’ll be more or less imperceptible to listeners. But if you do it right, they’ll also be robust against removal since they are very close to an important part of the audio.
Here comes the diagram:
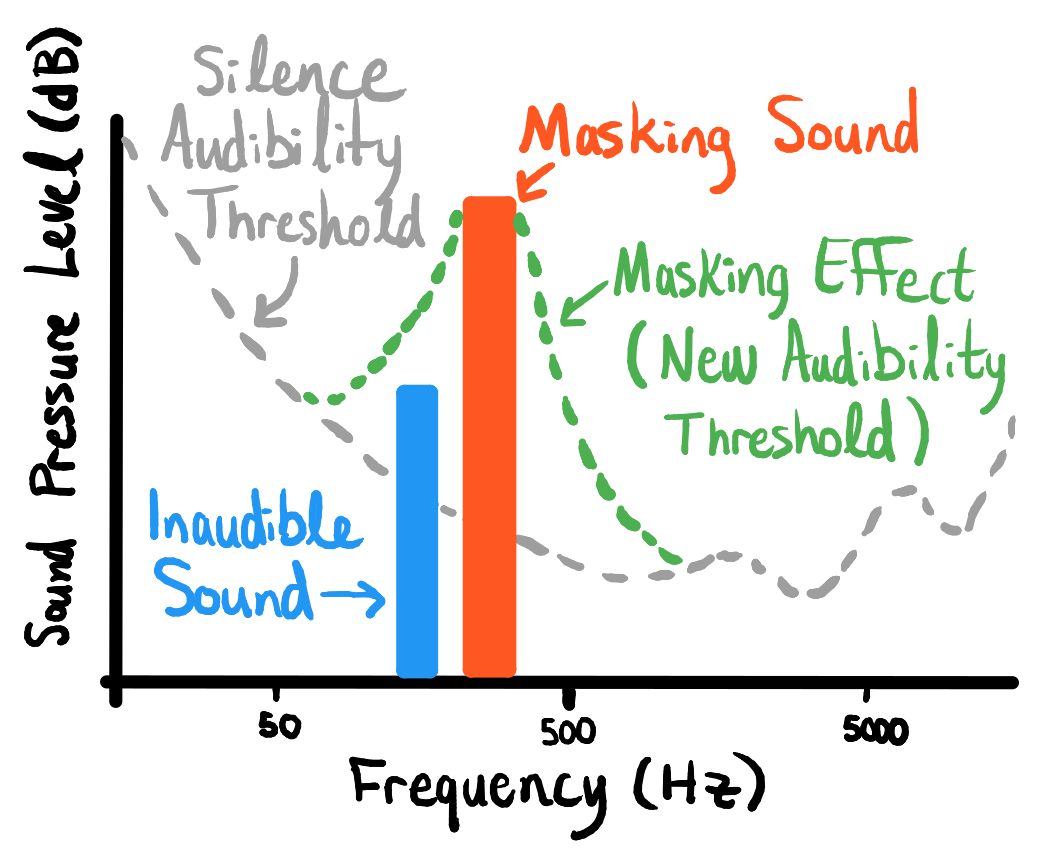
Diagram showing how lesser tones are “masked” by nearby peaks.
It’s intuitive but the challenge was no doubt creating a machine learning model that can locate candidate waveform sections and automatically produce the appropriate, yet inaudible, audio tones that carry the identifying information. Then it has to reverse that process while remaining robust to common sound manipulations like those mentioned above.
Here are two examples they provided. See if you can figure out which one is watermarked. Hover here to see the answer in your status bar.
I can’t tell the difference and even inspecting the waveforms pretty closely I wasn’t able to find any obvious anomalies. I’m not handy enough with a spectrum analyzer these days to really get in there, but I suspect that’s where you might see something. At any rate if their claim that data indicating generation by Resemble is encoded more or less irreversibly into one of these clips, I’d say it’s a success.
PerTh will soon roll out to all of Resemble’s customers, and to be clear right now it only can mark and detect the company’s own generated speech. But if they did it, others probably will too — and chances are these engines will soon be inextricably linked to the speech generation models themselves. Malicious actors will always find a way around such things, but putting barriers in place ought to help curb some of that behavior.
Audio is special in this way, though, and similar tricks won’t work for text or images. So expect to remain in the uncanny valley for a while in those domains.


