

AI helps historians complete ancient Greek inscriptions damaged over millennia – TechCrunch
As if being a scholar in ancient Greek wasn’t hard enough fundamentally, the primary texts they rely on are frequently damaged beyond repair, being as they are thousands of years old. Historians may have a powerful new tool in Ithaca, a machine learning model built by DeepMind that makes surprisingly accurate guesses at missing words and the location and date of the text. It’s an unusual application of AI, but one that demonstrates how useful it can be outside the tech world.
The problem of incomplete ancient texts goes across many disciplines in which experts work with degraded materials. The original document might be made of stone, clay, or papyrus, written in Akkadian, ancient Greek, or Linear A, and describe anything from a grocer’s bill to a hero’s journey. What they all have in common though is the damage accumulated over thousands of years.
Gaps where the text is worn or torn off are often called lacunae, and can be as short as a missing letter or as long as a chapter, or indeed an entire story. Filling them in can be trivial or impossible, but you have to start somewhere — and that’s where Ithaca is meant to help.
Trained on an huge library of ancient Greek texts, Ithaca (named after Odysseus’s home island) not only can say what a missing word or phrase is likely to be, but can also take a shot at how old it is and where it was written. It’s not going to go filling in a whole epic cycle on its own — it’s meant to be a tool for those who work with these texts, not a solution.
A paper published in the journal Nature demonstrates its efficacy, using as an example some decrees from Periclean Athens. Thought to have been written in around 445 BC, Ithaca suggested based on its textual analysis that they were actually from 420 BC or so — in line with more recent evidence. It might not sound like a lot, but imagine if the Bill of Rights was actually written 20 years later!
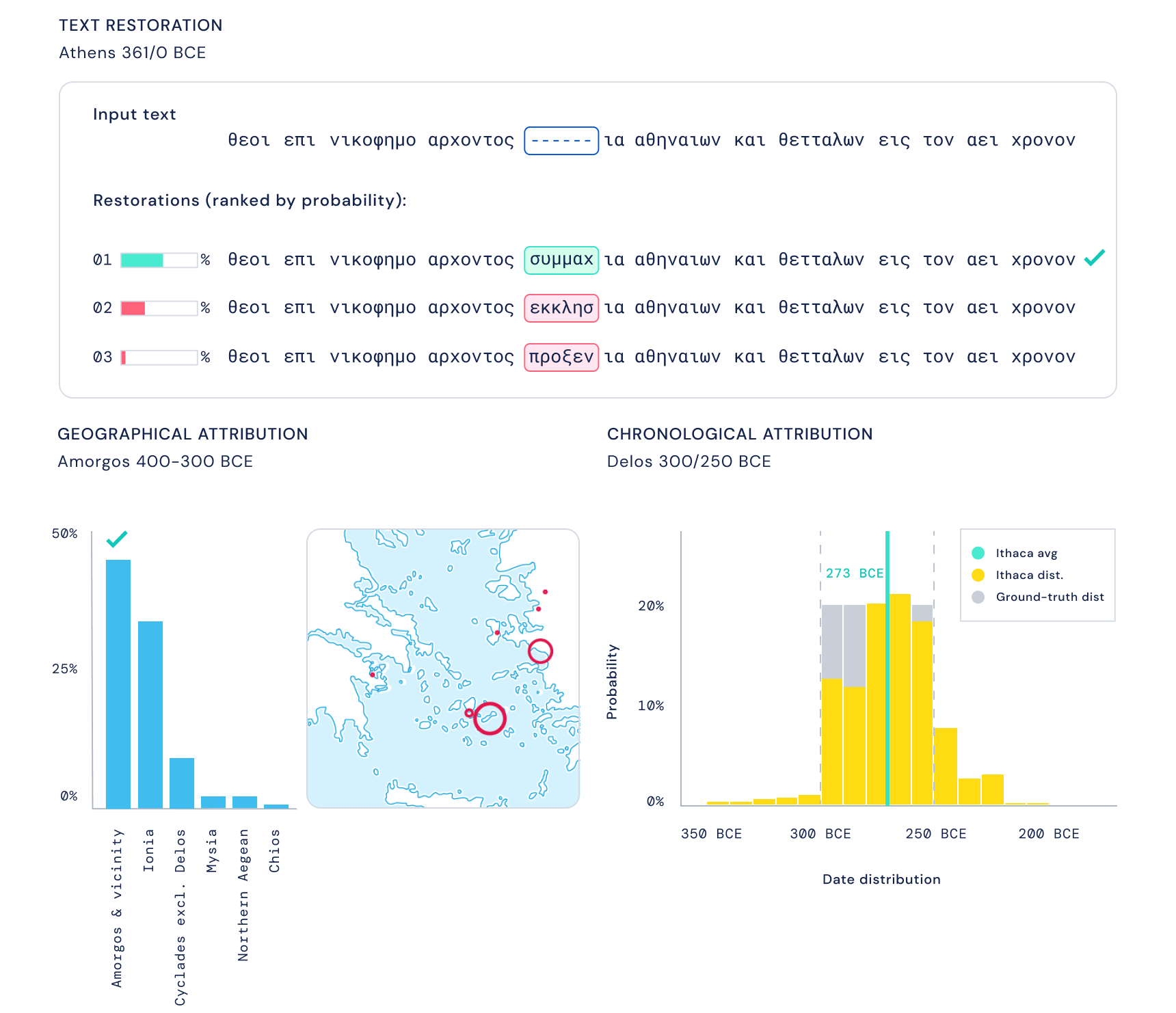
Image Credits: DeepMind
As for the text itself, experts in the study got it about 25 percent right on the first pass, not exactly stellar, though of course text restoration is not meant to be an afternoon lark but a long term project. Paired with Ithaca, however, they quickly achieved 72 percent accuracy. This is often found to be the case in other situations where humans ultimately are more accurate but can have their process sped up by quickly eliminating dead ends or suggesting a starting point. In medical data it can be easy to oversee an abnormality the AI might flag quickly — but ultimately it is human expertise that perceives the details and finds the right answer.
You can test out a pared down version of Ithaca here, if you have some lacunae-ridden ancient Greek text handy, or use one of their provided examples to see how it fills in requested gaps. For longer pieces or more than 10 letters missing, try it out in this Colab notebook. The code is available at this GitHub page.
Though ancient Greek is an obvious and fruitful area in which for Ithaca to start, the team is already hard at work on other languages as well. Akkadian, Demotic, Hebrew and Mayan are all on the list, and hopefully more will be added over time.
“Ithaca illustrates the potential contribution of natural language processing and machine learning in the humanities,” said Ion Androutsopoulos, a professor at Athens University who worked on the project. “We need more projects like Ithaca to further showcase this potential, but also suitable courses and teaching material to educate future researchers who will have a better joint understanding of both the humanities and AI methods.”


