

Implement differential privacy to power up data sharing and cooperation – TechCrunch
Traditionally, companies have relied upon data masking, sometimes called de-identification, to protect data privacy. The basic idea is to remove all personally identifiable information (PII) from each record. However, a number of high-profile incidents have shown that even supposedly de-identified data can leak consumer privacy.
In 1996, an MIT researcher identified the then-governor of Massachusetts’ health records in a supposedly masked dataset by matching health records with public voter registration data. In 2006, UT Austin researchers re-identifed movies watched by thousands of individuals in a supposedly anonymous dataset that Netflix had made public by combining it with data from IMDB.
In a 2022 Nature article, researchers used AI to fingerprint and re-identify more than half of the mobile phone records in a supposedly anonymous dataset. These examples all highlight how “side” information can be leveraged by attackers to re-identify supposedly masked data.
These failures led to differential privacy. Instead of sharing data, companies would share data processing results combined with random noise. The noise level is set so that the output does not tell a would-be attacker anything statistically significant about a target: The same output could have come from a database with the target or from the exact same database but without the target. The shared data processing results do not disclose information about anybody, hence preserving privacy for everybody.
To implement differential privacy, one should not start from scratch, as any implementation mistake could be catastrophic for the privacy guarantees.
Operationalizing differential privacy was a significant challenge in the early days. The first applications were primarily the provenance of organizations with large data science and engineering teams like Apple, Google or Microsoft. As the technology becomes more mature and its cost decreases, how can all organizations with modern data infrastructures leverage differential privacy in real-life applications?
Differential privacy applies to both aggregates and row-level data
When the analyst cannot access the data, it is common to use differential privacy to produce differentially private aggregates. The sensitive data is accessible through an API that only outputs privacy-preserving noisy results. This API may perform aggregations on the whole dataset, from simple SQL queries to complex machine learning training tasks.
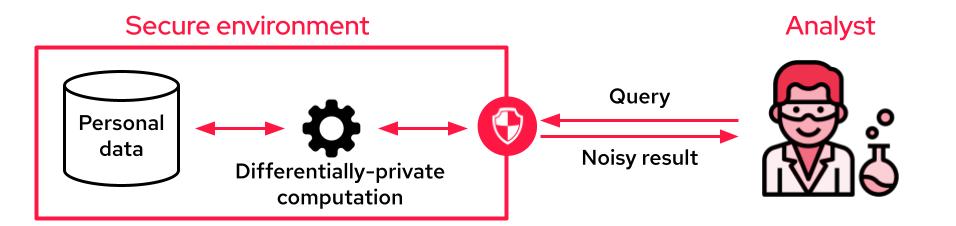
A typical setup for leveraging personal data with differential privacy guarantees. Image Credits: Sarus
One of the disadvantages of this setup is that, unlike data masking techniques, analysts no longer see individual records to “get a feel for the data.” One way to mitigate this limitation is to provide differentially private synthetic data where the data owner produces fake data that mimics the statistical properties of the original dataset.


